In the INIT Lab, we focus on natural user interaction for children. Many of these modalities, such as touch, gesture, and speech, involve some type of recognition process to understand what the user input is. To determine how accurate a recognizer is, there are several methods. One of these methods is using binary classifiers, as used in the MTAGIC project. Binary classification is classifying the elements of a set into two groups based on a classification rule. For example, classifying the outputs of a gesture recognizers to being recognized right or wrong is an example of the binary classification method. Word Error Rate (WER) is another method to determine the accuracy of a recognizer when the input is more complex. WER is commonly used as a metric for computing the performance of a speech recognition system (e.g., automatic speech recognition, or ASR). However, this method is useful in other contexts as well, such as handwriting, machine translation or other types of recognition.
The WER is derived from the Levenshtein Distance algorithm, calculated as the minimum edit distance between two strings. WER is used for both text and speech. In speech, it is defined as the minimum edit distance between an ASR hypothesis and the reference transcription. The formula for WER is as below, summing up the three types of errors (substitution, deletion, and insertion), over the length of the string:
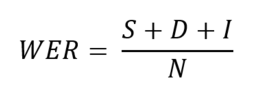
In which:
- S is the number of substitutions (misrecognition of one word for another),
- D is the number of deletions (words missed by the recognition system),
- I is the number of insertions (words introduced into the text output by the recognition system),
- N is the number of words in the reference.
The intuition behind deletion and insertion is to think about what edits would one have to make to get from the reference to the hypothesis.
Accuracy can be computed as the inverse of WER:
![]()
WER is a useful metric to compute and compare the performance of different systems, as well as for evaluation of a system. However, it has some drawbacks that need to be considered. One problem is that this formula does not consider the effect that different types of errors may have on the outcome, i.e., some errors can be more disruptive, while other errors may be corrected more easily. Another problem is that this formula cannot distinguish a substitution error from a combined deletion plus insertion error. Therefore, the common belief that a lower word error rate shows more accuracy in recognition may not always be true, so further work and consideration may be needed to decide on the best metric based on the context.
I am a 2nd year Ph.D. student majoring in Human-Centered Computing in the CISE department of the University of Florida. I believe studying and implementing WER has helped me improve my understanding of methods of recognition, especially in the context of ASR or other natural interaction technologies. It has also helped me learn the reasons behind the WER formulation, and its drawbacks. I am looking forward to a deeper investigation of WER and its implementation using Levenshtein distance algorithm.