
Over the past months, I have continued my work on the understanding gestures project by working on developing a set of new articulation features based on how children make touchscreen gestures. Our prior work has shown that children’s gestures are not recognized as well as adults’ gestures, which led us to perform further investigation on how children’s gestures differ from those of adults. In one of our studies, we computed the values of 22 existing articulation features to improve our understanding. An articulation feature is a quantitative measure of some aspect of the way the user creates the gesture. These features are generally either geometric (such as the total amount of ink used or the or the area of the bounding box surrounding the gesture) or temporal (such as the total time taken to produce the gesture or the average speed). In that paper, we showed there was a significant effect of age on the values of many of the features, illustrating differences between children’s and adults’ gestures.
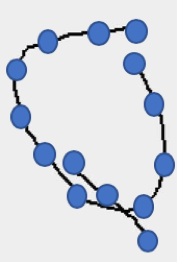
Though we found many differences between children and adults’ gestures, I noticed there were several behaviors that were often present in children’s gestures which were not captured by the features we had used. For example, children’s gestures often do not connect the endpoints of their strokes as well as adults do, as shown in the following “Q” gesture produced by a 5-year-old in one of our studies:
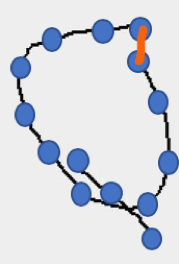
I developed a list of several behaviors like this one that I wanted to capture as new articulation features. For this blog post, I’ll focus on the feature measuring the distance between endpoints of strokes that should be connected, which I’ll call joining error. Using the “D” gesture as an example, the value we would want to compute is the total distance indicated by the orange line below:
To compute this feature, my first idea was to develop an algorithm to detect which ends of strokes should be joined, then measure the distance between them. However, even though we know what the gestures should look like, creating an algorithm to measure this feature would be a difficult computer vision problem. I thought I could look at the distance between points and then assume that if the distance between them was less than a threshold, they should be joined. However, this doesn’t work in all cases. What if some endpoints are less than the threshold, but not supposed to be joined? Many of the features we wanted to compute required similar challenges making them different to design an algorithm for.
Despite this difficulty, I realized that I could just easily look at any gesture, see the joining errors, and mark the distance I wanted to measure. Therefore, I decided to manually annotate all the gestures to calculate the new features. Because there were more than 20,000 gestures, I needed to develop a tool to help me complete the annotations in a timely manner.
I created a tool that plots out all the gestures in a given set and allows me to click to mark the features I’m interested in. The program detects the size of the screen and determines how many gestures to put on the screen. Then I can click each pair of endpoints that should be joined for measuring joining error, and my software automatically logs the distance between the points as well as information about the gesture. The following shows a mockup of the program I developed:

I was able to annotate five different features of over 20,000 gestures using my tool in a few weeks, whereas if I had manually examined each gesture individually, it would have probably taken several months. Furthermore, since I was visually inspecting each gesture, I had confidence that I was measuring exactly the quantity I wanted. Working on this project has helped me learn how important it can be to create tools for streamlining work requiring repeated manual intervention.